📝 "Если проект не укладывается в сроки, то добавление рабочей силы задержит его ещё больше.
Adding manpower to a late software project makes it later."
—The Brooks's Law
📝 "Brooks' law is based on the idea that communications overhead is a significant factor on software projects, and that work on a software project is not easily partitioned into isolated, independent tasks. Ten people can pick cotton ten times as fast as one person because the work is almost perfectly partitionable, requiring little communication or coordination. But nine women can't have a baby any faster than one woman can because the work is not partitionable. Brooks argues that work on a software project is more like having a baby than picking cotton. When new staff are brought into a late project, they aren't immediately productive, and they must be trained. The staff who must train them are already productive, but they lose productivity while they're training new staff. Brooks argues that, on balance, more effort is lost to training and additional coordination and communications overhead than is gained when the new staff eventually becomes productive."
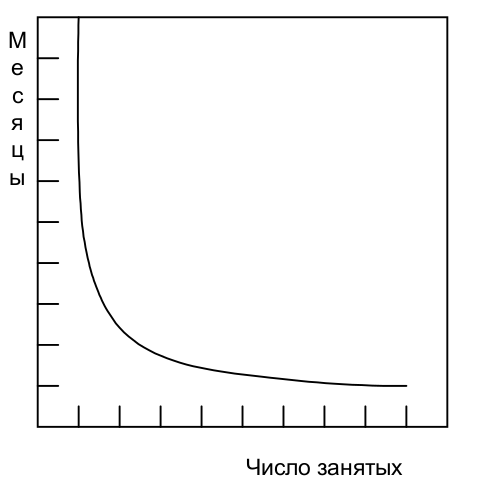
📝 "Число занятых [специалистов] и число месяцев [в термине человеко-месяц] являются взаимозаменяемыми величинами лишь тогда, когда задачу можно распределить среди ряда работников, которые не имеют между собой взаимосвязи (рис. 2.1).
Men and months [in term man-month] are interchangeable commodities only when a task can be partitioned among many workers with no communication among them (Fig. 2.1)."
—"The Mythical Man-Month Essays on Software Engineering Anniversary Edition" by Frederick P. Brooks, Jr., перевод ООО Издательство "Питер"
Сравните это с
📝 "Microservices' main benefit, in my view, is enabling parallel development by establishing a hard-to-cross boundary between different parts of your system."
Frederick Brooks формулирует противоречие. С одной стороны:
📝 "Выше я доказал, что само число разработчиков, действия которых нужно согласовывать, оказывает влияние на стоимость проекта, поскольку значительная часть издержек вызвана необходимостью общения и устранения отрицательных последствий разобщенности (системная отладка). Это также наводит на мысль, что желательно разрабатывать системы возможно меньшим числом людей. Действительно, опыт разработки больших программных систем, как правило, показывает, что подход с позиций грубой силы влечет удорожание, замедленность, неэффективность, а создаваемые в результате системы не являются концептуально целостными. Список, иллюстрирующий это, бесконечен: OS/360, Exec 8, Scop 6600, Multics, TSS, SAGE и другие.
I have earlier argued that the sheer number of minds to be coordinated affects the cost of the effort, for a major part of the cost is communication and correcting the ill effects of miscommunication (system debugging). This, too, suggests that one wants the system to be built by as few minds as possible. Indeed, most experience with large programming systems shows that the brute-force approach is costly, slow, inefficient, and produces systems that are not conceptually integrated. OS/360, Exec 8, Scope 6600, Multics, TSS, SAGE, etc.—the list goes on and on."
—"The Mythical Man-Month Essays on Software Engineering Anniversary Edition" by Frederick P. Brooks, Jr., перевод ООО Издательство "Питер"
Таким же наблюдением делится и Sam Newman:
📝 "... небольшие команды, работающие с небольшим объемом исходного кода, как правило, показывают более высокую продуктивность.
... smaller teams working on smaller codebases tend to be more productive!"
—"Building Microservices. Designing Fine-Grained Systems" by Sam Newman, перевод ООО Издательство "Питер"
Но, с другой стороны:
📝 "В этом и состоит изъян идеи маленькой активной команды: для создания по-настоящему крупных систем ей потребуется слишком много времени. Посмотрим, как разработка OS/360 осуществлялась бы маленькой активной командой, допустим, из 10 человек. Положим, что они в семь раз более продуктивны средних программистов (что далеко от истины). Допустим, что уменьшение объема общения благодаря малочисленности команды позволило еще в семь раз повысить производительность. Допустим, что на протяжении всего проекта работает одна и та же команда. Таким образом, 5000/(10*7*7)=10, т.е. работу в 5000 человеко-лет они выполнят за 10 лет. Будет ли продукт представлять интерес через 10 лет после начала разработки или устареет благодаря стремительному развитию программных технологий?
This then is the problem with the small, sharp team concept: it is too slow for really big systems. Consider the OS/360 job as it might be tackled with a small, sharp team. Postulate a 10-man team. As a bound, let them be seven times as productive as mediocre programmers in both programming and documentation, because they are sharp. Assume OS/360 was built only by mediocre programmers (which is far from the truth). As a bound, assume that another productivity improvement factor of seven comes from reduced communication on the part of the smaller team. Assume the same team stays on the entire job. Well, 5000/(10 X 7 X 7 ) = 10; they can do the 5000 man-year job in 10 years. Will the product be interesting 10 years after its initial design? Or will it have been made obsolete by the rapidly developing software technology?"
—"The Mythical Man-Month Essays on Software Engineering Anniversary Edition" by Frederick P. Brooks, Jr., перевод ООО Издательство "Питер"
Возникает противоречие:
📝 "Дилемма представляется жестокой. Для эффективности и концептуальной целостности предпочтительнее, чтобы проектирование и создание системы осуществили несколько светлых голов. Однако для больших систем желательно поставить под ружье значительный контингент, чтобы продукт мог увидеть свет вовремя. Как можно примирить эти два желания?
The dilemma is a cruel one. For efficiency and conceptual integrity, one prefers a few good minds doing design and construction. Yet for large systems one wants a way to bring considerable manpower to bear, so that the product can make a timely appearance. How can these two needs be reconciled?"
—"The Mythical Man-Month Essays on Software Engineering Anniversary Edition" by Frederick P. Brooks, Jr., перевод ООО Издательство "Питер"
Добавим немного контекста:
📝 "Вторая ошибка рассуждений заключена в самой единице измерения, используемой при оценивании и планировании: человеко-месяц. Стоимость действительно измеряется как произведения числа занятых на количество затраченных месяцев. Но не достигнутый результат. Поэтому использование человеко-месяца как единицы измерения объема работы является опасным заблуждением.
Число занятых и число месяцев являются взаимозаменяемыми величинами лишь тогда, когда задачу можно распределить среди ряда работников, которые не имеют между собой взаимосвязи (рис. 2.1). Это верно, когда жнут пшеницу или собирают хлопок, но в системном программировании это далеко не так.
Рис. 2.1 Зависимость времени от числа занятых — полностью разделимая задача. Fig. 2.1 Time versus number of workers—perfectly partitionable task. The image source is "The Mythical Man-Month Essays on Software Engineering Anniversary Edition" by Frederick P. Brooks, Jr., "Chapter 2 The Mythical Man-Month", перевод ООО Издательство "Питер".¶
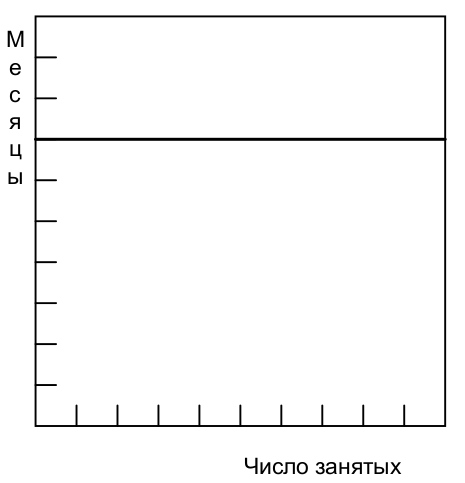
Если задачу нельзя разбить на части, поскольку существуют ограничения на последовательность выполнения этапов, то увеличение затрат не оказывает влияния на график (рис. 2.2). Чтобы родить ребенка требуется девять месяцев независимо от того, сколько женщин привлечено к решению данной задачи. Многие задачи программирования относятся к этому типу, поскольку отладка по своей сути носит последовательный характер.
Рис. 2.2 Зависимость времени от числа занятых — неразделимая задача. Fig. 2.2 Time versus number of workers—unpartitionable task. The image source is "The Mythical Man-Month Essays on Software Engineering Anniversary Edition" by Frederick P. Brooks, Jr., "Chapter 2 The Mythical Man-Month", перевод ООО Издательство "Питер".¶
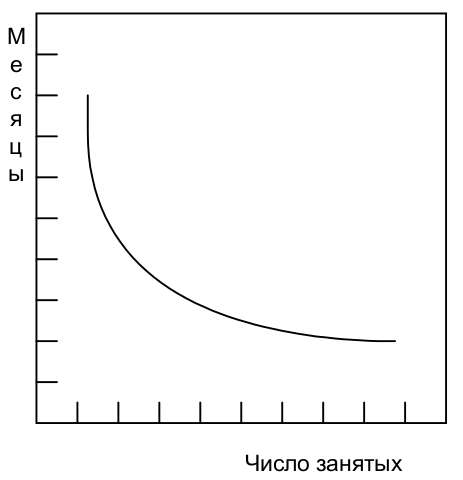
Для задач, которые могут быть разбиты на части, но требуют обмена данными между подзадачами, затраты на обмен данными должны быть добавлены к общему объему необходимых работ. Поэтому достижимый наилучший результат оказывается несколько хуже, чем простое соответствие числа занятых и количества месяцев (рис. 2.3).
Рис. 2.3 Зависимость времени от числа занятых — разделимая задача, требующая обмена данными. Fig. 2.3 Time versus number of workers—partitionable task requiring communication. The image source is "The Mythical Man-Month Essays on Software Engineering Anniversary Edition" by Frederick P. Brooks, Jr., "Chapter 2 The Mythical Man-Month", перевод ООО Издательство "Питер".¶
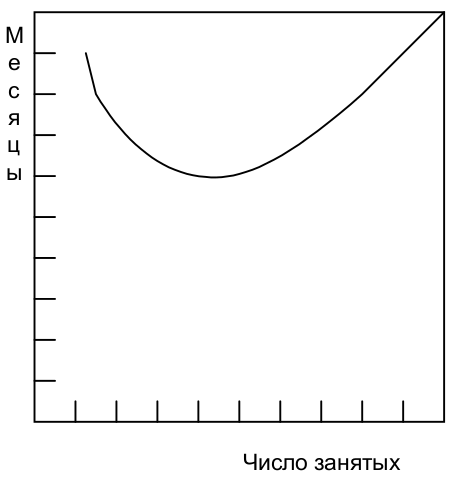
Дополнительная нагрузка состоит из двух частей — обучения и обмена данными. Каждого работника нужно обучить технологии, целям проекта, общей стратегии и плану работы. Это обучение нельзя разбить на части, поэтому данная часть затрат изменяется линейно в зависимости от числа занятых.
С обменом данными дело обстоит хуже. Если все части задания должны быть отдельно скоординированы между собой, то затраты возрастают как n(n-1)/2. Для трех работников требуется втрое больше попарного общения, чем для двух, для четырех — вшестеро. Если помимо этого возникает необходимость в совещаниях трех, четырех и т.д. работников для совместного решения вопросов, положение становится еще хуже. Дополнительные затраты на обмен данными могут полностью обесценить результат дробления исходной задачи и привести к положению, описываемому рисунком 2.4.
Рис. 2.4 Зависимость времени от числа занятых — задача со сложными взаимосвязями. Fig. 2.4 Time versus number of workers—task with complex interrelationships. The image source is "The Mythical Man-Month Essays on Software Engineering Anniversary Edition" by Frederick P. Brooks, Jr., "Chapter 2 The Mythical Man-Month", перевод ООО Издательство "Питер".¶
Поскольку создание программного продукта является по сути системным проектом — практикой сложных взаимосвязей, затраты на обмен данными велики и быстро начинают преобладать над сокращением сроков, достигаемым в результате разбиения задачи на более мелкие подзадачи. В этом случае привлечение дополнительных работников не сокращает, а удлиняет график работ.
The second fallacious thought mode is expressed in the very unit of effort used in estimating and scheduling: the man-month. Cost does indeed vary as the product of the number of men and the number of months. Progress does not. Hence the man-month as a unit for measuring the size of a job is a dangerous and deceptive myth. It implies that men and months are interchangeable.
Men and months are interchangeable commodities only when a task can be partitioned among many workers with no communication among them (Fig. 2.1). This is true of reaping wheat or picking cotton; it is not even approximately true of systems programming.
When a task cannot be partitioned because of sequential constraints, the application of more effort has no effect on the schedule (Fig. 2.2). The bearing of a child takes nine months, no matter how many women are assigned. Many software tasks have this characteristic because of the sequential nature of debugging.
In tasks that can be partitioned but which require communication among the subtasks, the effort of communication must be added to the amount of work to be done. Therefore the best that can be done is somewhat poorer than an even trade of men for months (Fig. 2.3).
The added burden of communication is made up of two parts, training and intercommunication. Each worker must be trained in the technology, the goals of the effort, the overall strategy, and the plan of work. This training cannot be partitioned, so this part of the added effort varies linearly with the number of workers.
Intercommunication is worse. If each part of the task must be separately coordinated with each other part/ the effort increases as n(n-1)/2. Three workers require three times as much pairwise intercommunication as two; four require six times as much as two. If, moreover, there need to be conferences among three, four, etc., workers to resolve things jointly, matters get worse yet. The added effort of communicating may fully counteract the division of the original task and bring us to the situation of Fig. 2.4.
Since software construction is inherently a systems effort—an exercise in complex interrelationships—communication effort is great, and it quickly dominates the decrease in individual task time brought about by partitioning. Adding more men then lengthens, not shortens, the schedule."
—"The Mythical Man-Month Essays on Software Engineering Anniversary Edition" by Frederick P. Brooks, Jr., перевод ООО Издательство "Питер"
Мы остановились на дилемме: с одной стороны, чем меньше численность людей, принимающих проектные решения, тем выше их продуктивность.
С другой стороны, чем больше людей задействовано в разработке, тем скорее продукт сможет выйти на рынок.
Проанализируем о том, как эту дилемму можно решить.
Решение этой дилеммы становится возможным с качественным отделением архитектуры от реализации (с чем отлично справляются сетевые границы Bounded Contexts):
📝 "Архитектура и разработка должны быть тщательно разделены. Как сказал Блау (Blaauw), "архитектура говорит, что должно произойти, а разработка - как сделать, чтобы это произошло". В качестве простого примера он приводит часы, архитектура которых состоит из циферблата, стрелок и заводной головки. Ребенок, освоивший это архитектуру, с одинаковой легкостью может узнать время и по ручным часам, и по часам на колокольне. Исполнение же и его реализация описывают, что происходит внутри: передача усилий и управление точностью каждым из многих механизмов.
Architecture must be carefully distinguished from implementation. As Blaauw has said, "Where architecture tells what happens, implementation tells how it is made to happen." He gives as a simple example a clock, whose architecture consists of the face, the hands, and the winding knob. When a child has learned this architecture, he can tell time as easily from a wristwatch as from a church tower. The implementation, however, and its realization, describe what goes on inside the case—powering by any of many mechanisms and accuracy control by any of many."
—"The Mythical Man-Month Essays on Software Engineering Anniversary Edition" by Frederick P. Brooks, Jr., перевод ООО Издательство "Питер"
Harlan Mills' Proposal (Предложение Харлана Миллза) было опубликовано в:
Mills, H., "Chief programmer teams, principles, and procedures," IBM Federal Systems Division Report FSC 71-5108, Gaithersburg, Md., 1971.
Baker, F. T., "Chief programmer team management of production programming," IBM Sys. J., 11, 1 (1972).
📝 "Предложение Харлана Миллза дает свежее и творческое решение. Миллз предложил, чтобы на каждом участке работы была команда разработчиков, организованная наподобие бригады хирургов, а не мясников. Имеется в виду, что не каждый участник группы будет врезаться в задачу, но резать будет один, а остальные оказывать ему всевозможную поддержку, повышая его производительность и плодотворность.
При некотором размышлении ясно, что эта идея приведет к желаемому, если ее удастся осуществить. Лишь несколько голов занято проектированием и разработкой, и в то же время много работников находится на подхвате. Будет ли такая организация работать? Кто играет роль анестезиологов и операционных сестер в группе программистов, а как осуществляется разделение труда? Чтобы нарисовать картину работы такой команды с включением всех мыслимых видов поддержки, я позволю себе вольное обращение к метафорам.
A proposal by Harlan Mills offers a fresh and creative solution. Mills proposes that each segment of a large job be tackled by a team, but that the team be organized like a surgical team rather than a hog-butchering team. That is, instead of each member cutting away on the problem, one does the cutting and the others give him every support that will enhance his effectiveness and productivity.
A little thought shows that this concept meets the desiderata, if it can be made to work. Few minds are involved in design and construction, yet many hands are brought to bear. Can it work? Who are the anesthesiologists and nurses on a programming team, and how is the work divided? Let me freely mix metaphors to suggest how such a team might work if enlarged to include all conceivable support."
—"The Mythical Man-Month Essays on Software Engineering Anniversary Edition" by Frederick P. Brooks, Jr., перевод ООО Издательство "Питер"
Обратите внимание на слова "эта идея приведет к желаемому, если ее удастся осуществить".
Именно эту задачу успешно решает концепция Bounded Context, позволяя совместить большой размер коллектива и продуктивность, т.е., осуществить масштабирование команд без ущерба производительности.
📝 "... мы стремимся к тому, чтобы сервисы создавались в результате разбиения системы на такие части, при которых темпы развития внутри сервисов были намного выше темпов развития между сервисами.
... we aim to ensure our services are decomposed such that the pace of change inside a service is much higher than the pace of change between services."
—"Building Microservices. Designing Fine-Grained Systems" by Sam Newman, перевод ООО Издательство "Питер"
📝 "One case study was particularly interesting. The team had made the wrong choice, using microservices on a system that wasn't complex enough to cover the Microservice Premium. The project got in trouble and needed to be rescued, so lots more people were thrown onto the project. At this point the microservice architecture became helpful, because the system was able to absorb the rapid influx of developers and the team was able to leverage the larger team numbers much more easily than is typical with a monolith. As a result the project accelerated to a productivity greater than would have been expected with a monolith, enabling the team to catch up. The result was still a net negative, in that the software cost more staff-hours than it would have done if they had gone with a monolith, but the microservices architecture did support ramp up."
Наверное, идея обязательной согласованности организации и архитектуры может быть неплохо проиллюстрирована на примере Amazon и Netflix. В Amazon довольно рано начали понимать преимущества владения командами полным жизненным циклом управляемых ими систем. Там решили, что команды должны всецело распоряжаться теми системами, за которые они отвечают, управляя всем жизненным циклом этих систем. Но в Amazon также знали, что небольшие команды могут работать быстрее больших. Это привело к созданию команд, которые можно было бы накормить двумя пиццами. Это стремление к созданию небольших команд, владеющих полным жизненным циклом своих сервисов, и стало основной причиной того, что в Amazon была разработана платформа Amazon Web Services. Для обеспечения самодостаточности своих команд компании понадобилось создать соответствующий инструментарий. Этот пример был взят на вооружение компанией Netflix и с самого начала определил формирование ее структуры вокруг небольших независимых команд, образуемых с прицелом на то, что создаваемые ими сервисы также будут независимы друг от друга. Тем самым обеспечивалась оптимизация скорости изменения архитектуры систем. Фактически в Netflix разработали организационную структуру для желаемой архитектуры создаваемых систем.
Netflix and Amazon
Probably the two poster children for the idea that organizations and architecture should be aligned are Amazon and Netflix. Early on, Amazon started to understand the benefits of teams owning the whole lifecycle of the systems they managed. It wanted teams to own and operate the systems they looked after, managing the entire lifecycle. But Amazon also knew that small teams can work faster than large teams. This led famously to its two-pizza teams, where no team should be so big that it could not be fed with two pizzas. This driver for small teams owning the whole lifecycle of their services is a major reason why Amazon developed Amazon Web Services. It needed to create the tooling to allow its teams to be self-sufficient. Netflix learned from this example, and ensured that from the beginning it structured itself around small, independent teams, so that the services they created would also be independent from each other. This ensured that the architecture of the system was optimized for speed of change. Effectively, Netflix designed the organizational structure for the system architecture it wanted."
—"Building Microservices. Designing Fine-Grained Systems" by Sam Newman, перевод ООО Издательство "Питер"
я хотел бы добавить еще одно высказывание от разработчиков популярного микросервисного фреймворка go-kit:
📝 "Почему микросервисы? Практически вся современная разработка программного обеспечения ориентирована на единственную цель - улучшить время выхода на рынок. Микросервисы представляют собой эволюцию модели сервис-ориентированной архитектуры, которая элегантно устраняет организационные противоречия, предоставляя вашим инженерам и командам автономию, необходимую им для непрерывной доставки, итерации и улучшения.
Why microservices? Almost all of contemporary software engineering is focused on the singular goal of improving time-to-market. Microservices are an evolution of the service-oriented architecture pattern that elegantly eliminate organizational friction, giving your engineers and teams the autonomy they need to continuously ship, iterate, and improve."
На самом деле, если у вас армейская дисциплина среди разработчиков, то нет необходимости укреплять сетевыми границами пределы автономности команд, поскольку границами автономности команды является Bounded Context, который не обязательно должен быть выражен микорсервисом(-ами).
📝 "In theory, you don't need microservices for this if you simply have the discipline to follow clear rules and establish clear boundaries within your monolithic application; in practice, I've found this to be the case only very rarely.)"
Сетевые границы решают проблему, известную как creeping coupling или abstraction leak. А это позволяет снизить квалификационные требования к разработчикам, тем более, что Microservices First обычно имеет экономическую целесообразность только при задействовании большого количества разработчиков.
📝 "Обмен данными между самими сервисами ведется через сетевые вызовы, чтобы упрочить обособленность сервисов и избежать рисков, сопряженных с тесными связями.
All communication between the services themselves are via network calls, to enforce separation between the services and avoid the perils of tight coupling."
—"Building Microservices. Designing Fine-Grained Systems" by Sam Newman, перевод ООО Издательство "Питер"
Знаете, почему не бывает больших червяков?
Любое беспозвоночное животное не может быть бесконечно большим, поскольку на определенном пороге сила его тяжести превысит предел его прочности.
Рост силы тяжести опережает рост прочности.
Чтобы увеличение массы организма стало возможным, в нем должен появиться скелет, который выполняет опорную функцию.
По этой же причине бумажный кораблик хорошо держит форму, но если его пропорционально увеличить в несколько раз, то он рухнет под собственной тяжестью без фермы жесткости.
По этой же причине невозможно фрактально увеличить село до размеров крупного города, не обеспечив в нем транспортные магистрали и узлы связи.
Эту проблему хорошо сформулировал Galileo Galilei в теории theory of Beam Bending:
Discorsi e dimostrazioni matematiche, intorno à due nuoue scienze. Leiden: appresso gli Elsevirii, 1638. The image source is "Galileo's Beam Experiment"¶
📝 "Many mathematicians before Galileo had dealt with the problem of statics – how forces are transmitted by structural members.
Galileo proposed a new science, the study of the strength of materials, that considered how the size and shape of structural members affects their ability to carry and transmit loads.
He discovered that as the length of a beam increases, its strength decreases, unless you increase the thickness and breadth at an even greater rate.
You cannot, therefore, simply double or triple the dimensions of a beam, and expect it to carry double or triple the load.
This led Galileo to recognize what we now call the scaling problem – there are limits to how big nature can make a tree, or an animal, for beyond a certain limit, the branches of the tree or the limbs of the animal, will break under their own weight.
The illustration of a cantilever beam demonstrates Galileo’s discovery that the breaking force on a beam increases as the square of its length."
Масса балки зависит от ее объема (кубатура), а прочность - от сечения (квадратура). Т.е. масса возрастает на одно изменение больше прочности.
Попытка фрактально увеличивать численность Scrum/Nexus-команд равносильна попытке создать беспозвоночное животное с массой динозавра.
Основная тяжесть, под которой рушится прочность коллектива, формируется коммуникативной нагрузкой (з-н Брукса: n(n-1)/2).
Если предыдущий пример показался вам неубедительным, то давайте попробуем представить себе управление воздушным движением без диспетчеров.
Ну, такие... самоорганизующиеся экипажи.
Чтобы пилоты во время полета сами между собой договаривались о том, как они будут расходиться, какие эшелоны они будут занимать, в какой очередности они будут производить посадку и взлет...
Причем, гипотетически это еще было бы осуществимо где-то в районе малозагруженных аэропортов.
Но при этом возрастет когнитивная нагрузка на пилота.
Ни один из пилотов, в условиях управления воздушным судном, не обладает ресурсами внимания достаточными для достижения целостного понимания картины воздушного движения.
Эту когнитивную нагрузку с него снимает диспетчер управления воздушным движением.
А теперь попробуйте представьте себе что-то подобное в Шереметьево.
А если какое-то одно воздушное судно терпит бедствие и нуждается в аварийной посадке?
📝 "At Spotify there is a separate operations team, but their job is not to make releases for the squads - their job is to give the squads the support they need to release code themselves; support in the form of infrastructure, scripts, and routines.
They are, in a sense, "building the road to production".
<...>
We also have a chief architect role, a person who coordinates work on high-level architectural issues that cut across multiple systems.
He reviews development of new systems to make sure they avoid common mistakes, and that they are aligned with our architectural vision.
The feedback is always just suggestions and input - the decision for the final design of the system still lies with the squad building it."
SAFe создан известным автором по аналитике Dean Leffingwell, и, наверное, поэтому SAFe хорошо регламентирует процессы, предшествующие этапу реализации ПО в условиях масштабируемой Agile-разработки.
В книге "Agile Software Requirements: Lean Requirements Practices for Teams, Programs, and the Enterprise" by Dean Leffingwell, которая вышла в печать в том же году, в котором он выпустил первый релиз SAFe, Dean Leffingwell убедительно обосновывает, что аналитики и архитекторы должны быть частью системной команды.
📝 "Architects: Many agile teams do not contain people with titles containing the word architect [The best architectures, requirements, and designs emerge from self-organizing teams.], and yet architecture does matter to agile teams.
In these cases, the local architecture (that of the component, service, or feature that the team is accountable for) is most often determined by the local teams in a collaborative model.
In this way, it can be said that "architecture emerges" from the activities of those teams.
At the system level, however, architecture is often coordinated among system architects and business analysts who are responsible for determining the overall structure (components and services) of the system, as well as the system-level use cases and performance criteria that are to be imposed on the system as a whole.
For this reason, it is likely that the agile team has a key interface to one or more architects who may live outside the team.
(We'll discuss this in depth in Chapter 20.)
<...>
Some of these QA personnel will live outside the team, while others (primarily testers) will have likely been dispatched to live with the product team.
There, they work daily with developers to test new code and thereby help assure new code quality on a real-time basis.
In addition, as we'll see later, QA personnel are involved with the development of the system-level testing required to assure overall system quality and conformance to nonfunctional, as well as functional, requirements.
<...>
Other specialists and supporting personnel: Other supporting roles may include user-experience designers, documentation specialists, database designers and administrators, configuration management, build and deployment specialists, and whomever else is necessary to develop and deploy a whole product solution.
—Agile Software Requirements Lean Requirements Practices for Teams, Programs, and the Enterprise (Agile Software Development Series) by Dean Leffingwell
Для такого решения есть несколько причин:
В спринте возникают две цели (текущая и посторонняя):
Реализация текущего системного инкремента.
Анализ и проектирование (т.е. Prediction-активности в виде PBR, Spike и Planning) будущего системного инкремента.
Источником работы аналитиков являются стейкхолдеры, а результатом работы - требования (под руководством Product Owner, разумеется), т.е. PBI.
В то время как для команды разработки источником работы являются PBI (в состоянии DOR), а результатом работы - Системный Инкремент.
Получается, что две команды работают несинхронно, над разными целями, и производят разные артефакты.
Аналитики работают вне цикла реализации Системного Инкремента, опережая его в среднем на пару спринтов.
PBI, не производящий Системного Инкремента, но производящий артефакты, необходимые для доведения другого PBI до состояния DOR, традиционно называется Spike.
Spike нацелен на достижение цели будущих спринтов, поэтому его присутствие в текущем спринте отвлекает от цели текущего спринта, повышает когнитивную нагрузку и затрудняет управление Team Backlog.
Говоря архитектурным языком, налицо все признаки падения Cohesion, который восстанавливается, как известно, путем декомпозиции.
Для малочисленного коллектива (тем более, для Single Team Agile) эта нагрузка не превышает накладные расходы на содержание отдельного Program Backlog.
Но, по мере роста численности коллектива, накладные расходы на содержание отдельного Program Backlog начинают уже окупаться.
Системные инкременты, производимы командами, нуждаются в интеграции. Было бы неэффективно каждой команде погружаться в подробности целостной картины потребностей интеграции, при этом дублируя друг друга.
Поэтому, аналитику, архитектуру и UX/UI Design, в таком случае, выводят в отдельный цикл производства, известный сегодня как Program Management (который следует отличать от Program Management в PMBoK).
Получается два каскадных цикла, при этом, первый цикл (Program Backlog) создает артефакты, необходимые для достижения DOR для второго цикла (Team Backlogs), который, в свою очередь, уже производит системный инкремент.
Говоря о проблемах масштабирования Agile-команд, мне очень интересной показалась ещё одна его книга, которая вышла 4-мя годами ранее:
"Scaling Software Agility: Best Practices for Large Enterprises" by Dean Leffingwell
📝 "The second dimension of the team and technical agility competency is teams of Agile teams.
Even with good, local execution, building enterprise-class solutions typically requires more scope and breadth of skills than a single Agile team can provide.
Therefore, Agile teams operate in the context of an ART, which is a long-lived team of Agile teams.
The ART incrementally develops, delivers, and (where applicable) operates one or more solutions (Figure 6-5)."
📝 "System Architect/Engineering is an individual or team that defines the overall architecture of the system.
They work at a level of abstraction above the teams and components and define Non-Functional Requirements (NFRs), major system elements, subsystems, and interfaces."
📝 "System Teams typically assist in building and supporting DevOps infrastructure for development, continuous integration, automated testing, and deployment into the staging environment.
In larger systems they may do end-to-end testing, which cannot be readily accomplished by individual Agile teams."
📝 "Shared Services are specialists—for example, data security, information architects, Database Administrators (DBAs)—who are necessary for the success of an ART but cannot be dedicated to a specific train."
📝 "With the right architecture, elements of the system may be released independently.
Figure 8-8 illustrates an autonomous delivery system that was architected to enable system elements to be released independently."
📝 "Figure 8-8. Architecture impacts the ability to release system elements independently"
—"SAFe® 5.0: The World's Leading Framework for Business Agility" by Richard Knaster, Dean Leffingwell
Отдельно стоит выделить книгу "Agile Practice Guide" by Project Management Institute, 2017, поскольку эта книга является мощным оружием в руках аналитиков и архитекторов в вопросах организации качественных процессов.
Автором книги является Project Management Institute (PMI), обладающий неоспоримым авторитетом в глазах менеджмента.
Книга достаточно грамотная, и затрагивает острые вопросы интеграции аналитической и архитектурной активности в Agile-разработку.
В общем, если вы где-то услышите фразу "Architecture vs. Agile", то самое время вспомнить об этой книге.
Учитывая, что Disciplined agile delivery (DAD) сопровождается и развивается by Project Management Institute (PMI), интеграция его практик вызвает, как правило, меньше всего возражений со стороны менеджмента.
📝 "Agile projects for complex systems attempt to manage cost by prioritizing the most important capabilities for early realization.
If an organization manages the development and maintenance of its entire portfolio of software systems as a single system, managed by spend rate rather than total spending, then the organization can, in principle, manage that portfolio of systems as a continuing agile development, analogous to managing a highly iterative "Kanban" maintenance effort."
—"ISO/IEC/IEEE 12207:2017 Systems and software engineering - Software life cycle processes"
Интересна она, прежде всего, тем, что открыто говорит о проблемах Nexus, которые можно решить путем заимствования практик у SAFe.
Одним из наиболее узких мест Nexus является отсутствие масштабирования аналитической работы (сбор требований) в problem space.
Команды масштабируются, а бизнес-анализ, в лице единственного Product Owner, - нет.
Scrum, как известно, оставляет Product Owner с этой проблемой наедине, предлагая ему самостоятельно решать эту проблему путем делегации полномочий в случаях, когда аналитическая работа становится узким горлышком.
📝 "it's hard for one Product Owner to deal with too many teams...
In real life, these Product Owners are typically accountable for the value delivered by these multiple teams and rely upon a lot of assistance from the Development Teams in order to deal with the challenge of scale."
📝 "In multi-team programs, this one Product Owner may delegate the work to Product Owners that represent him or her on subordinate teams, but all decisions and direction come from the top-level, single Product Owner.
—"Jeff Sutherland's Scrum Handbook" by Jeff Sutherland
Статья подчеркивает ограниченность масштабирования Nexus по этой причине и предлагает к рассмотрению SAFe-практики:
📝 "As Nexus is designed to be a lightweight framework, with a more limited scope than SAFe, its not surprising that there are a lot more elements in SAFe that Nexus doesn't say anything about.
Some of these can be useful in your context, some not necessarily.
Think Architectural Runway, Innovation and Planning iteration, Team-level Kanbans, DevOps, Continuous Delivery pipeline, System Architect, Business Owner, Features/Enablers, Epics."
В числе прочего, упоминается и выделенная роль системного архитектора, поскольку в масштабируемом Agile возникают вопросы одновременного достижения как интеграции инкремента продукта, так и автономности команд.
В статье много лестных отзывов о Program Kanban:
📝 "Program Kanban.
SAFe includes one of the most powerful techniques to help improve flow and collaboration across a team of teams - a Kanban Board that takes a cross-team perspective.
I started using this technique back in 2009 and it's one I "don't leave home without".
Nexus doesn't include a Nexus-level Kanban board but it's a very nice complementary practice to consider.
Read more here"
Здесь автор ссылается на другую свою статью "Scaling Scrum with Nexus and Kanban" by Yuval Yeret, где предлагает интегрировать Program Management в самую легковесную scaled Scrum модель разработки Nexus, подобно тому, как это сделано в SAFe.
📝 "This will include all stages of work in the Nexus - ranging from Value discovery..."
Хотя в Scrum и можно выстроить хорошо отлаженные процессы, но это требует настолько деликатной работы, что я бы предпочел рассматривать сразу SAFe даже для маленьких команд (минимальную его конфигурацию - Essential Safe):
📝 "With awareness and appropriate adaptations, XP does scale.
Some problems can be simplified to be easily handled by a small XP team.
For others, XP must be augmented.
The basic values and principles apply at all scales.
The practices can be modified to suit your situation."
—"Extreme Programming Explained" 2nd edition by Kent Beck, "Chapter 15. Scaling XP :: Conclusion"
Во втором издании "Extreme Programming Explained", Kent Beck предлагает механизм масштабирования команд, который в точности реализует Program Management на основе Harlan Mills' Proposal.
📝 "Creating and maintaining a community of one hundred is a much different job than creating and maintaining a community of twelve, but it is done all the time."
—"Extreme Programming Explained" 2nd edition by Kent Beck, "Chapter 15. Scaling XP"
📝 "If just using a smaller team doesn't work, turn the big programming problem into several smaller problems, each solvable by a small team.
First solve a small part of the problem with a small team.
Then divide the system along its natural fracture lines and begin working on it with a few teams.
Partitioning introduces the risk that the pieces won't fit on integration, so integrate frequently to reconcile differing assumptions between teams.
This is a conquer-and-divide strategy instead of a divide-and-conquer strategy.
Sabre Airline Solutions, profiled in the next chapter, uses this strategy extensively.
The goal of conquer-and-divide is to have teams that can each be managed as if they are the only team to limit coordination costs.
Even so, the whole system needs to be integrated frequently.
The occasional exceptions to this illusion of independence are managed as exceptions.
If the exceptions become the norm and the teams have to spend too much time coordinating, look to the system to see if there are ways of restructuring it to return the teams to independence.Only if this fails is the overhead of large-project management appropriate.
In summary, faced with the apparent need for a large team, first ask if a small team can solve the problem.
If that doesn't work, begin the project with a small team, then split the work among autonomous teams."
—"Extreme Programming Explained" 2nd edition by Kent Beck, "Chapter 15. Scaling XP :: Number of People"
Each team had an architecture representative on a Scrum of Scrum architecture team led by the Business Unit Lead Architect
The enterprise architecture team had Business Unit Lead Architects led by the CTO who had senior management commitment to 10% of all points in every sprint dedicated to architectural improvement (technical debt remediation, integration, branding, etc.)
The first keynote speaker was Ken Schwaber. Ken and Jeff Sutherland are the authors and founders of the Scrum agile methodology. Ken started by describing his experiences working with Scrum on large projects and several techniques he had successfully used in the early stages of the project life cycle.
Ken explained on one project how the team was very concerned with getting the overall architecture of the system proven in the early stages of development. Early project iterations (sprints in Scrum terminology) contained stories focused on proving the system architecture peppered with several real business cases. After several iterations, during which the architecture was continuously refined and tested, the team had a good sense of whether the architecture was sufficient for the demands of the business.
Scaling was then achieved by starting new teams with the founders of the original architecture team. With most of the architectural issues addressed, the new teams could focus on implementing business logic on top of the then stable architecture.
Program Management также присутствует в MSF и в FDD.
В RAD тоже аналитика является "upstream development activities".
RUP реализует спиральную модель.
В книге "Software Architecture in Practice" 4th edition by Len Bass, Paul Clements, Rick Kazman особый интерес представляют собою главы:
20.6 More on ADD Step 7: Perform Analysis of the Current Design and Review the Iteration Goal and Achievement of the Design Purpose
Use of an Architectural Backlog
Use of a Design Kanban Board
Интерес они вызыват прежде всего потому, что:
📝 "The drivers become part of an architectural design backlog that you should use to perform the different design iterations.
When you have made design decisions that account for all of the items in the backlog, you’ve completed this round."
—"Software Architecture in Practice" 4th edition by Len Bass, Paul Clements, Rick Kazman
📝 "The output of ADD is not an architecture complete in every detail, but an architecture in which the main design approaches have been selected and vetted.
It produces a "workable" architecture early and quickly, one that can be given to other project teams so they can begin their work while the architect or architecture team continues to elaborate and refine."
—"Software Architecture in Practice" 3d edition by Len Bass, Paul Clements, Rick Kazman
Humberto Cervantes и Rick Kazman, в книге "Designing Software Architectures: A Practical Approach", которая была посвящена ADD 3.0, предлагают заводить "architectural design backlog" даже в Scrum:
📝 "For example, when using Scrum, the sprint backlog and the design backlog are not independent:
Some features in the sprint backlog may require architecture design to be performed, so they will generate items that go into the architectural design backlog.
These two backlogs can be managed separately, however.
The design backlog may even be managed internally, as it contains several items that are typically not discussed or prioritized by the customer (or product owner).
Also, additional architectural concerns may arise as decisions are made.
For example, if you choose a reference architecture, you will probably need to add specific architectural concerns, or quality attribute scenarios derived from them, to the architectural design backlog.
An example of such a concern is the management of sessions for a web application reference architecture."
—"Designing Software Architectures: A Practical Approach" by Humberto Cervantes, Rick Kazman
Т.е. речь идет опять же, об отдельном Backlog для активностей, предшествующих фазе реализации Системного Инкремента.
Хотя Program Management и выполняет роль опорного хребта коммуникативной нагрузки коллектива, момент его внедрения в процессы разработки должен быть своевременным и оправданным, т.е. издержки на его содержание должны покрываться выгодами от его внедрения.
Кроме того, концентрация всех архитектурных задач на уровне Program Management может привести к образованию узкого горлышка.
Одним из способов решения этой задачи является децентрализация архитектурных решений об интеграции ограниченных контекстов.
Карта ограниченных контекстов (Context Map) позволяет сократить количество возможных коммуникационных путей в коллективе и снизить коммуникативную нагрузку.
Например, если подмножество какого-то публичного интерфейса Ограниченного Контекста используется как Customer/Supplier только одним другим Ограниченным Контекстом, то команде не нужно общаться с командами остальных Ограниченных Контекстов по поводу изменения этого подмножества.
Построение топологии команд по Ограниченным Контекстам позволяет сфокусировать полезную коммуникативную нагрузку внутри команды и уменьшить контрпродуктивную коммуникативную нагрузку по интеграции между командами, тем самым повышая уровень автономности команд.
Более лучшего эффекта можно достигнуть используя CDC-Tests:
📝 "About consumer-driven contract testing, we identified two reasons:
development teams have communication obstacles when several people working on one microservice (e.g., over 8 people, see Figure 6 (Right)) and
microservices systems extensively use third party resources [118]."
📝 "We use some techniques from DDD, particularly event storming, to understand and model the domains in our business context.
At a more technical level, we use Pact for contract testing services and inter-team communication.
Pact has really helped us to adopt a clear, defined approach to testing services, setting expectations across all teams about how to test and interact with other teams."
—"Team Topologies: Organizing Business and Technology Teams for Fast Flow" by Matthew Skelton, Manuel Pais
📝 "Contract tests are a big win when it comes to enabling teams to work and deploy independently, but they also require some level of coordination.
Consumer contract tests are of very little value unless they're verified against the provider, and a provider can't write contract tests for their system without working with the consumer team to get the tests added to the consumer project.
Contracts are not a replacement for good communication between or within teams.
In fact, contracts require collaboration and communication.
One could make the argument that this is one of the main reasons to leverage Pact and enforce communication pathways in large internal and external development organizations.
Contracts are not a magical silver bullet that will allow you to hide in your developer caves and toss built artifacts at each other until everything passes.
It is important for all teams to be invested in the process.
One of the most common reasons that Pact fails to be successfully adopted in an organisation is a lack of buy in from all parties.
Collaborate about the problems, collaborate over the design, and keep the communication channels open."
Таким образом, независимо от того, существует ли у команд Program Management, или же команды имеет фрактальную структуру, CDC-Tests позволяют в значительной мере управлять коммуникативной нагрузкой на команды и минизировать Проблему Брукса.
📝 "By keeping things team sized, we help to achieve what MacCormack and colleagues call "an 'architecture for participation' that promotes ease of understanding by limiting module size, and ease of contribution by minimizing the propagation of design changes."[MacCormack et al., "Exploring the Structure of Complex Software Designs."] In other words, we need a team-first software architecture that maximizes people's ability to work with it.
<...>
More than ever I believe that someone who claims to be an Architect needs both technical and social skills, they need to understand people and work within the social framework. They also need a remit that is broader than pure technology—they need to have a say in organizational structures and personnel issues, i.e. they need to be a manager too.[Kelly, "Return to Conway's Law."]"
— "Team Topologies: Organizing Business and Technology Teams for Fast Flow" by Matthew Skelton